Daten
Wie ist das Korpus aufgebaut?
Korpuskonturierung, Korpustypologie
Das Korpus ist eine Textsammlung, die für Belegsuchen im Bereich der lexikalischen, semantischen, metrischen, morphologischen und syntaktischen Fragestellungen aufbereitet wird. Das leitende Forschungsziel des Korpus besteht in der onomasiologischen Wortschatzbeschreibung des Mittelhochdeutschen.
Die Text- bzw. Datenakquisition erfolgt durch ein kontrolliertes Monitorkorpus, das kontinuierlich erweitert wird. Die aktuelle Größe ist 666 Texte und 329,376,195 Triples. Dabei werden homogene Parameter verwendet, im Gegensatz zur früheren opportunistischen Datenakquisition. Das bedeutet, dass die Datenerfassung nach bestimmten Vorgaben und Kriterien erfolgt.
Der Fokus des Korpus liegt hauptsächlich auf dem Mittelhochdeutschen, wobei auch Erweiterungen in Form von frühneuhochdeutschen Texten enthalten sind. Gelegentlich können auch Einsprengsel anderer Sprachen wie Latein vorkommen.
Das Korpus ist ein Referenzkorpus und enthält eine ausgewogene Mischung verschiedener Genres und Varietäten. Es gibt eine festgelegte Konturierung der Textsammlung, wobei alle Gattungen von Texten möglich sind. Zudem ist eine breite Streuung der Sprachräume gegeben, um eine vielfältige Datenbasis zu gewährleisten.
Der zeitliche Rahmen des Korpus umfasst nicht nur den Zeitraum von 1050 bis 1350, der als "Mittelhochdeutscher Basis-Daten-Bestand" bekannt ist, sondern erstreckt sich vielmehr von 1050 bis 1600. Man könnte die MHDBDB als "Textarchiv vor 1600" bezeichnen (in Ergänzung zum DTA) und es ermöglicht einen erweiterten zeitlichen Kontext für die Forschung.
Das Korpus wird linguistisch aufbereitet, indem eine Tokenisierung und Lemmatisierung der Texte erfolgt. Es werden auch teilweise Disambiguierungen vorgenommen, um Mehrdeutigkeiten aufzulösen. Zudem erfolgt eine Annotation der Daten.
Urheberrecht und Lizenzen
„Die Geburt des Lesers ist zu bezahlen mit dem Tod des Autors.“ (Barthes, Roland: Der Tod des Autors. In: Texte zur Theorie der Autorschaft. Hrsg. von Fotis Jannidis u.a. Stuttgart: Reclam 2000. S. 193.)
Das Urheberrecht gilt für die Urhebenden von Texten. Sie sind für die gesetzlich vorgegebene Dauer bis 70 Jahre nach dem Tod der Autor\*in geschützt und nicht gemeinfrei (vgl. §§ 60-61 UrhG-AT bzw. §§ 64-69 UrhG-DE). Der Urheberrechtsschutz für ein mittelalterliches Werk kann daher sicher als ‚abgelaufen‘ betrachtet werden. Wer ein Werk, für das die Schutzfrist abgelaufen ist, erlaubterweise (nach 70 Jahren post mortem auctoris) veröffentlicht, dem stehen die Verwertungsrechte am Werk wie einem Urheber zu. Dieses Schutzrecht erlischt 25 Jahre nach der Veröffentlichung.
Wissenschaftliche Editionen mediävistischer Texte müssen daher mit dem juristischen, dem Urheberrecht entnommenen Begriff der _editio princeps_ beleuchtet werden. Es handelt sich hier um eine Bestimmung des UrhG-AT und UrhG-DE, die besondere Schutzrechte aus der Erstveröffentlichung von Werken herleitet und die (gedruckte) Erstausgabe bzw. die erste Publikation eines literarischen Werkes bezeichnet.
Für die MHDBDB bedeutet das: Editionen, deren Erstveröffentlichung mehr als 25 Jahre zurückliegt, sind unproblematisch. Moderne Editionen, welche bereits einmal edierte Texte wieder edieren, sind ebenso gemeinfrei. Für jene Ausgaben, die in den vergangenen 25 Jahren erstveröffentlicht wurden, bedarf es hingegen noch einmal genauerer rechtlicher Prüfung.
Die MHDBDB veröffentlicht keinen Apparat/keine Kommentare im editionswissenschaftlichen Sinn, sondern den reinen Text mit eigenen Annotationen (RDF). Die Schöpfungshöhe der Werke ist daher tendenziell anders zu bewerten. Alle MHDBDB-Annotationen haben die Lizenz CC BY-NC-SA 4.0. Die E-Texte selbst sind individuell ausgezeichnet. Bei Werken, die der MHDBDB in Absprache mit den Herausgeber\*innen zur Verfügung gestellt wurden, wird eine eigene Lösung bereitgestellt.
Beispiel: Vlastimil Brom (Hg.): Di tutsch kronik von Behem lant (2012).
In welchem Format liegen die Daten vor?
Die E-Texte wurden ursprünglich in basalem, strukturangebendem TEI-XML kodiert (Strophe, Vers, Überschrift). Alle Dateien sind tokenisiert, d.h. alle Tokens sind mit einem Element "seg" mit eindeutiger ID ausgezeichnet. Von dort wird mittels Stand-off-Markup auf sämtliche Annotationen/Forschungsdaten/Metadaten im RDF-Format verwiesen. Kontrollierte Vokabularien (Begriffssystem, Namenssystem, Textreihentypologie) wurden als SKOS-Vokabulare realisiert. Die Lemmata sind nach den Vorgaben des OntoLex-Lemon-Lexicography-Modules kodiert. Die Vernetzung zwischen RDF- und TEI-Daten erfolgt mittels Web Annotation Vocabulary nach der Empfehlung des W3-Konsortiums. Sämtliche Annotationen können zur weiteren Verwendung unter heruntergeladen werden: github.com/Middle-High-German-Conceptual-Database/TEI-Texte
Kann man die Daten herunterladen?
Sämtliche Annotationen können zur weiteren Verwendung als TEI auf github heruntergeladen werden. Wo das Urheberrecht es erlaubt, stehen die E-Texte zusätzlich als PDF-Dateien zur Verfügung.
Semantische Modellierung in der MHDBDB
POS-Tagging
Die Texte sind weitestgehend mit part-of-speech-Tagging (POS-Tagging) versehen. Darunter versteht man die Zuordnung von Wörtern und Satzzeichen eines Textes zu Wortarten (englisch part of speech). de.wikipedia.org/wiki/Part-of-speech-Tagging Dies ermöglicht unter anderem, nur nach bestimmten Wortarten zu suchen. So kann man bei der Belegsuche etwa angeben, z.B. wenn man nicht alle Ergebnisse zu "minne" sehen möchte, kann man "Minne + Eigenname" angeben und bekommt dann Stellen angezeigt, an denen "Frau Minne" auftaucht. Die POS-Annotationen folgen den Vorgaben des OntoLex-Lemon-Lexicography-Modules (https://www.w3.org/2019/09/lexicog/) des W3C.
Begriffssystem
Das namensgebende Begriffssystem der MHDBDB basiert auf dem System von Rudolf Hallig und Walther von Wartburg, das 1952 publiziert worden ist. Klaus M. Schmid, Begründer der MHDBDB, wandte dieses System in seiner Dissertationsschrift auf den Wortschatz des Frauendienst Ulrichs von Lichtenstein an (Schmidt 1972). Dieses Projekt, das noch mit Lochkarten und Fortran umgesetzt wurde, ist der Grundstein der heutigen MHDBDB.
Mit den Jahren veränderte das Team der MHDBDB das Hallig-Wartburg’sche Begriffssystem sukzessive und passte es dem Korpus sowie zeitlichen Veränderungen an. Nach heutigem Verständnis unpassende Kategorien wie „Rassen“ (gemeint bei HW: Zwerge, Riesen) wurden ersetzt, zahlreiche neue Kategorien erschlossen.
Im letzten Schritt des Relaunchs wurde das alte Begriffssystem in Form eines kontrollierten Vokabulars in SKOS (Simple Knowledge Organization System) realisiert. SKOS erlaubt nicht nur Polyhierarchien (hierarchische Strukturen, in der eine Klasse mehr als eine übergeordnete Klasse haben kann), sondern auch die Vergabe verschiedener Labels (Synonyme), Sprachen und weiterer Anmerkungen.
Sämtliche Lemmata bzw. Tokens der heutigen MHDBDB sind diesem neuen Begriffssystem zugeordnet. Jedes Token verweist im Stand-off-Markup (https://www.digitale-edition.at/o:konde.171) auf mindestens eine (meist mehrere) Kategorien im Baum. Das mittelhochdeutsche Wort „katze“ etwa ist nicht nur der Bedeutung „Säugetiere + Haustiere“ zugewiesen, sondern auch „Waffen + Belagerung + Schlacht“, denn bei einer „katze“ handelt es sich auch um ein Belagerungswerkzeug. Will man nun nur nach Kriegsmaschinerie suchen, interessiert sich aber nicht für die Tiere, so kann man die Belegstellensuche beispielsweise mit dem Begriff „Belagerung“ kombinieren.
Namenssystem/Onomastikon
Ab 1992 wurden zahlreiche Texte, die der Kieler Linguist Horst Pütz für ein Namenwörterbuch digitalisiert hatte, in die MHDBDB übernommen. Die Namenskategorien wurden in das Begriffssystem (s.o.) integriert und die Datenbank erhielt ihren finalen Namen MHDBDB.
Dieses Vorgehen war aus technischen Gründen in der damaligen Zeit notwendig, lässt sich heute aber fachlich nicht mehr begründen, da Bedeutungen (Semantik) und Namen (Onomastik) verschiedene Ebenen sind. Aus diesem Grund wurden alle 83 Namenskategorien wie z.B. „Waffen/Namen“ (Balmunc, Excalibur, Mimminc) wieder aus dem Begriffssystem herausgelöst und in ein eigenes in SKOS realisiertes kontrolliertes Vokabular überführt.
SKOS erlaubt nicht nur Polyhierarchien, sondern auch die Vergabe verschiedener Labels (Synonyme), Sprachen und weiterer Anmerkungen.
Textreihen/Gattungen
Die Texte werden weiterhin einer oder mehreren Textreihen (Gattungen) der Textreihentypologie zugewiesen. (Ausführliche Erklärung siehe Katharina Zeppezauer-Wachauer und Marco Heiles, Eine digitale Textreihentypologie für deutschsprachige Texte des Mittelalters und der Frühen Neuzeit. Showcase eines kontrollierten Vokabulars in SKOS, in: Mittelalter. Interdisziplinäre Forschung und Rezeptionsgeschichte 6 (2023), S. 6–39, DOI: [https://doi.org/10.26012/mittelalter-30680](https://doi.org/10.26012/mittelalter-30680).)
So ist es möglich, beispielsweise nur nach Belegen in der Gattung bzw. Textreihe "Artusroman" zu suchen. Dabei ist die Differenzierung in der Facettensuche abwärts-kompatibel ist, d.h. alle Hauptkategorien liefern auch alle Ergebnisse in unteren Kategorien. Beispiel: „Großepik“ liefert z.B. Belege aus „Heldenepos“, „Höfischer Roman“, „Prosaroman“, „Schwankroman“, „Textzyklus mit Rahmenerzählung“ sowie allen Kindern dieser Kategorien.
Darüber hinaus ist die Systematik polyhierarchisch, es gibt also häufig verschiedene übergeordnete Parent-Kategorien. Beispiel: Die Textreihe „Vaterunser“ hat als übergeordnete Datensätze „Erstlesetexte“, „Gebet“, „Geistliches Meisterlied“ sowie „Liturgie“.
Metadaten
Die MHDBDB nutzt [BIBFRAME 2.0](https://www.loc.gov/bibframe/) (RDF) für bibliografische Metadaten.
Es gibt folgende Instanzen auf Werk-/Textebene:
- Werke
- Editionen oder Digitale Editionen dieser Werke
- Elektronische Texte dieser Editionen (meist aus den 1990ern)
- MHDBDB-E-Texte, die entweder auf Editionen, digitalen Editionen oder elektronischen Texten von Editionen beruhen
[CIDOC-CRM](https://www.cidoc-crm.org/) (RDF) wird für weitere Metadatenobjekte (Personen, Orte, Ereignisse) genutzt, wobei Ereignisse derzeit vor allem als Autorlebensdaten und Werkentstehungsdaten im Einsatz sind.
Sämtliche Metadaten der MHDBDB sind ans Semantic Web bzw. an Normdaten angebunden und als Linked-Open-Data (LOD) verfügbar gemacht.
![Metadaten der MHDBDB in Relation zueinander]
Abb.: MHDBDB Main Ontology
Ontologien
Die Zusammenhänge der Annotationen sind in der MHDBDB Main Ontology abgebildet, die auch auf GitHub verfügbar ist. https://github.com/Middle-High-German-Conceptual-Database/mhdbdb-main-ontology-2023
Zitiervorschlag
Mittelhochdeutsche Begriffsdatenbank (MHDBDB). Universität Salzburg. Koordination: Katharina Zeppezauer-Wachauer. Seit 1992. URL: [http://www.mhdbdb.plus.ac.at/](http://www.mhdbdb.plus.ac.at/) (Abrufdatum). DOI: 10.60646/MHDBDB.
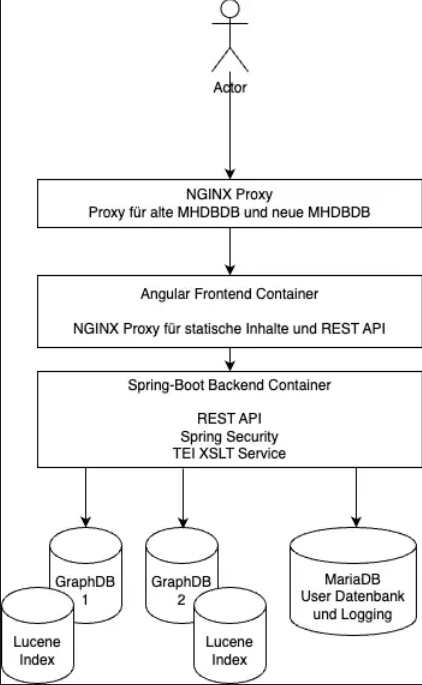
Infrastruktur, Architektur und Design
Lucene: Lucene wird für die Volltextsuche verwendet und ist über einen GraphDB Connector mit der Datenbank verbunden. Es ermöglicht eine schnelle Suche über den gesamten Korpus und liefert die passenden Referenzen zu den Belegstellen.
Angular: Komponentenbasierte Architektur: Angular verwendet eine komponentenbasierte Architektur, die die Wiederverwendbarkeit von Code erleichtert und die Entwicklung modular und übersichtlich macht.
Two-Way Data Binding: Diese Funktion erleichtert die Synchronisation zwischen Modell und Ansicht, was die Entwicklung effizienter macht und die Notwendigkeit reduziert, zusätzlichen Code für die Aktualisierung der Benutzeroberfläche zu schreiben.
TypeScript-Basis: Angular wird mit TypeScript, einer Erweiterung von JavaScript, entwickelt. TypeScript bietet strenge Typisierung, was zu einer besseren Codequalität, einfacherer Fehlerbehebung und höherer Entwicklerproduktivität führt.
Umfangreiche Werkzeugunterstützung: Angular bietet eine Vielzahl integrierter Werkzeuge für Testing, Building und Optimierung von Anwendungen, was die Entwicklungszeit verkürzt.
Starkes Ökosystem: Durch die breite Nutzung und Unterstützung von Google hat Angular ein starkes Ökosystem, das reichhaltige Ressourcen, Bibliotheken und eine aktive Community bietet.
Integration mit modernen Webtechnologien: Angular ist kompatibel mit den neuesten Standards des Web Development und lässt sich gut mit anderen Technologien und Frameworks integrieren.
TypeScript: Angular und TypeScript sind eng miteinander verbunden, da Angular in TypeScript geschrieben ist. TypeScript bietet eine strengere Typisierung als JavaScript, was die Fehlerbehebung und Wartung erleichtert, besonders in großen Projekten. Dies führt zu einer höheren Codequalität und Skalierbarkeit.
GraphDB
GraphDB 10.3.3
Lizenzen der verwendeten Softwarekomponenten
GraphDB Enterprise Edition, Evaluation Lizenz für Universitäten
Architektur